Отказоустойчивый кластер
При создании отказоустойчивого кластера в Control Plane поднимаются 3 мастер-ноды, в то время как в стандартном кластере запускается одна мастер-нода. Это повышает доступность (availability) кластера в случае отказа одной или нескольких мастер-нод.
Важно
В случае создания стандартного кластера MWS не может гарантировать SLA.
При создании отказоустойчивого кластера сетевой балансировщик будет распределять трафик между всеми тремя нодами.
Балансировщик использует алгоритм Round-robin.
Чтобы включить отказоустойчивый кластер, на странице Создание кластера поставьте галочку в поле Отказоустойчивый кластер.
Если опция включена, то на странице настроек кластера в поле Отказоустойчивость будет стоять значение "Да".
Работоспособность кластера в случае отказа компонентов Control Plane
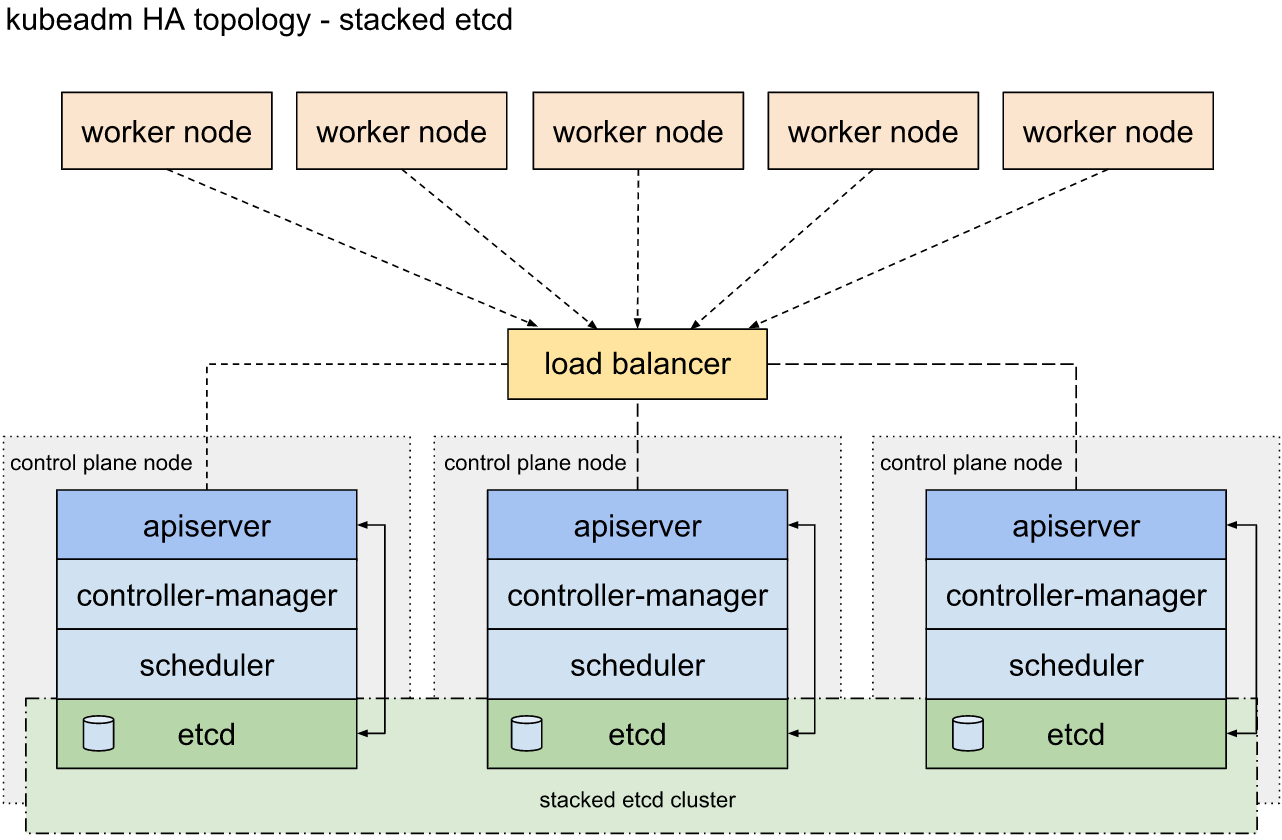
В случае отказа одной мастер-ноды, кластер продолжит работать в штатном режиме. Ни доступность клиентских сервисов, ни возможность разворачивать новые сервисы не пострадают.
В случае отказа двух или более мастер-нод, клиентские сервисы останутся доступны для пользователей, однако развертывание новых сервисов станет недоступно.
Если на одной мастер-ноде перестанет работать etcd, то кластер продолжит работать в штатном режиме.
Если etcd перестанет работать на двух или более мастер-нодах, то развертывание новых сервисов станет недоступно.
Если на одной или двух мастер-нодах перестанет работать какой-либо компонент Control Plane (Scheduler, API Server, Controller Manager), то кластер продолжит работать в штатном режиме.
Итого
Для работы кластера в штатном режиме требуется наличие как минимум двух рабочих etcd-реплик и всех работающих компонентов Control Plane (Scheduler, API Server, Controller Manager) хотя бы на одной мастер-ноде.